Hypermedia APIs on Rails: why DHH should “give a fk”
In a nutshell: directing your clients around your web API via link relations, rather than having them rely on URL conventions, is a good idea for exactly the same reason that Rails’ routing helpers are a good idea.
For the benefit of those not familiar with what routing helpers are: they’re helper functions for URL paths that Rails provides for use within your web app’s code as an alternative to hard coding those URLs into your links, redirects, tests, etc. Here’s a couple of example usages:
link_to widgets_path redirect_to dashboard_path
The idea is that by not hard-coding the actual URL, and relying on the indirection of a helper, you make it painless to change your application’s URL structures further down the line.
Given that the pain of hard-coding URLs within the application’s codebase is acknowledged by Rails developers, it seems pretty odd that we are still happy describing our web APIs to the outside world in terms of hard-code-able URL patterns.
By using links, you can describe your web API in terms of link relations and therefore encourage clients not to be hard-coded against any URL structures. This allows you to freely change them e.g. moving entire sections of your app onto a separate domain and clients remaining none-the-wiser. This helps you to scale your app, transparently test out changes to your API, and prevents your API succumbing to URL atrophy.
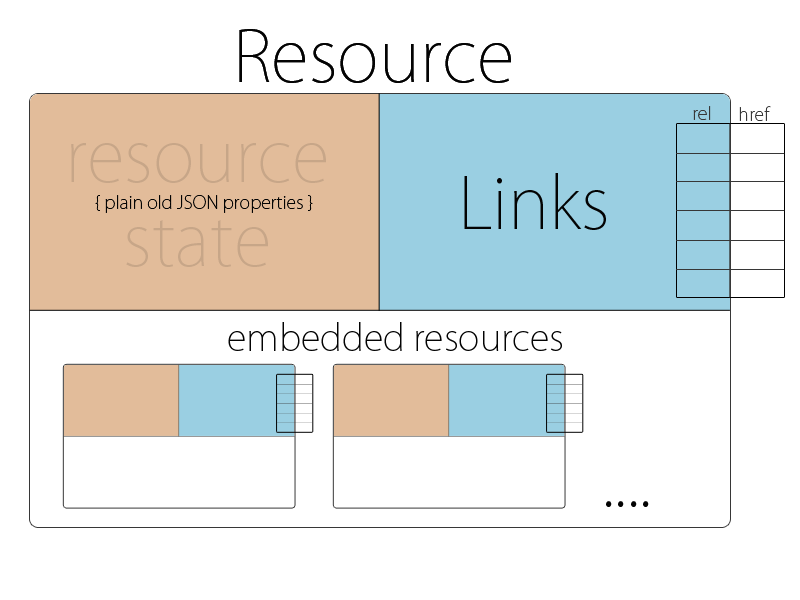
Hypermedia doesn’t have to be difficult or complicated - and to prove that I came up with a simple media type that adds linking on top of JSON. It’s called application/hal+json, and here’s how you would represent a widgets and dashboard link with it:
{
"_links": {
"widgets": { "href": "..." },
"dashboard": { "href": "..." }
},
... JSON as usual ...
}
Instead of hard-coding a URL, clients can now simply traverse over the link:
response = HTTP.get(this._links.widgets.href)
This is all hypermedia is really about; the “control” is in the message itself. Exactly the same principal as HTML, just applied to machine-consumable APIs. If you want to see an example API using hal+json, checkout the following link:
To be clear: there are many other benefits to hypermedia APIs that I have not covered here, but I think the above probably the hardest for someone like DHH to dismiss as “REST wankery”. I am planning on writing about the other benefits some time in the near future.
If you’re interested in exposing hal+json and you develop in ruby, I highly recommend Roar by Nick Sutterer. For other languages, you can checkout a the hal homepage for a list of available libraries.